写给自己在爬虫项目里面的一个快捷转换脚本
前段时间开始写爬虫的时候,不少朋友推荐了下面的传送门
**https://curl.trillworks.com/**什么样子先来瞅瞅看
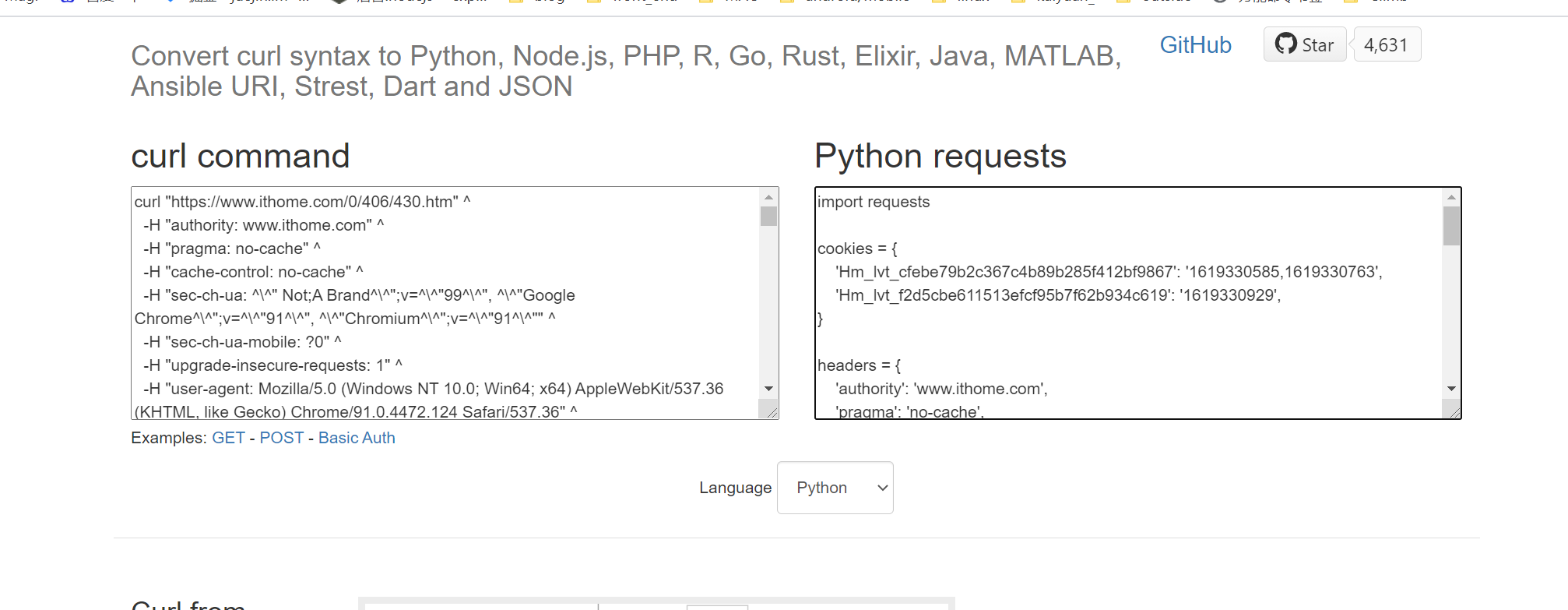
能够快速构造请求头,除了Postman,我最服气的就是它。
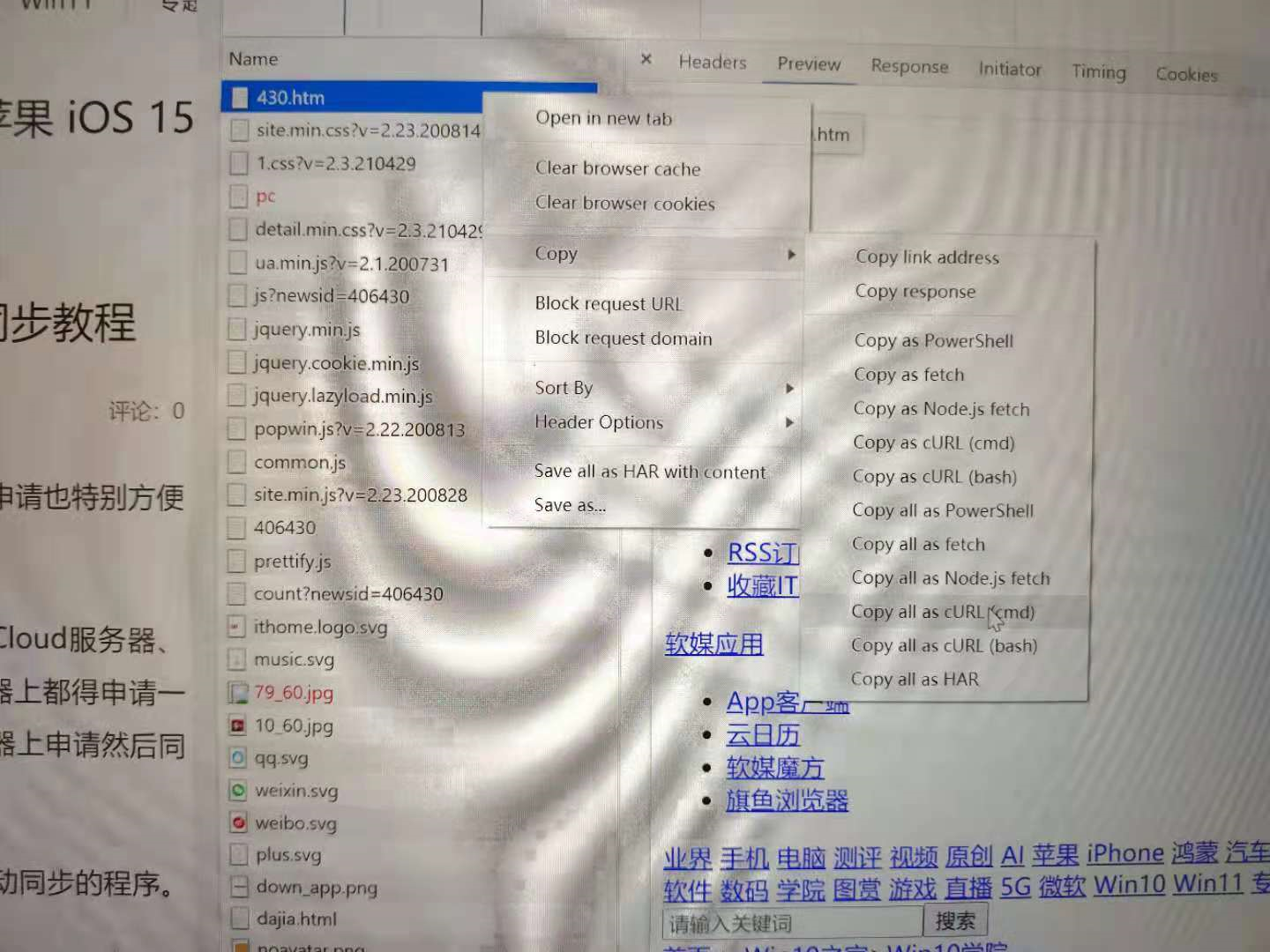
定位请求,右键复制curl,粘贴进入红框,绿框立刻自动生成py请求。
常年手动突然变自动,大幅提升效率,仿佛捡到宝贝。
思考
虽然但是,我还是觉得缺点什么。
不足在哪里?
从原生请求到生成python请求头,至少7步;
- 复制 Curl
- 打开 浏览器
- 打开 https://curl.trillworks.com/
- 粘贴 Curl
- 复制 自动生成py请求
- 粘贴 至编辑器
满打满算6步中间操作,偶尔用用还好,如果经常重复多遍,就不可忍耐了。
而且,过于依赖浏览器网页环境,在工作流不是一键好的事情,尤其是在一个国外的网站上。
从6到3
理清需求,从根源着手。
冷静研究一番网站的结构,把它的转换网页js翻了一遍,好消息是他的主要逻辑放在前端,js代码大概9000行, 经过一番抛头去尾,过滤无效变量,提取核心逻辑方法,改造一番,写进编辑器→Js。
Ok,Curl2Js 由此诞生。
整套流程缩短至3步
- 复制Curl
- 右键粘贴,运行 node curl.js -a "Curl Text"
转送Python调用获取参数
因为原项目的环境以Python为主,所以后面也将脚本顺理成章的转成Python脚本,过程也不复杂,python读取Js文件,并且实现传参调用,Py调用Js的方法有不少,这里选用了execjs来运行这段代码。
python
#读取并编译js文件,运行js内函数获得想要的结果
def getSignatureString(data):
jsstr = ReadJs()
ctx = execjs.compile(jsstr)
curl_response=json.dumps(ctx.call("convert", str(data) ) )
return curl_response
#读取JS文件,将js代码转换
def ReadJs():
jsfile = open("./curl.js","r")
codeline = jsfile.readline()
codestr=""
while codeline:
codestr =codestr +codeline
codeline =jsfile.readline()
return codestr
# Shell 获取参数并输出
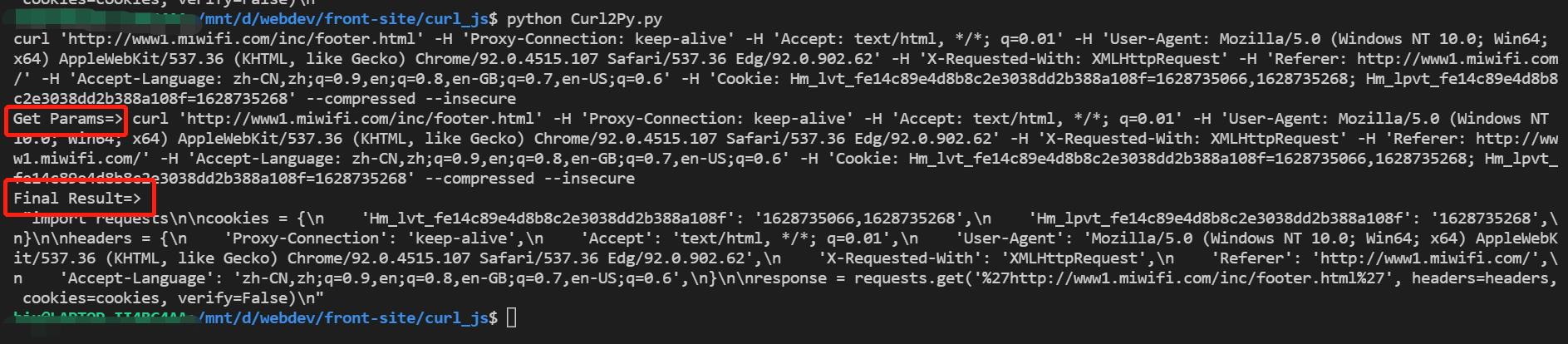
cook = input()
print('Get Params=>', cook)
result = getSignatureString( cook )
print( 'Final Result=>\n', result )使用效果
脚本地址
如果需要这个脚本的朋友,可以在点击博客右下角聊天窗口,回复curl脚本,我看到后会一一发送,也正好测试下,Hexo里面daovoice插件的交流效果,如果有更好的关于这个需求的扩展思路,也欢迎一起讨论。