一、追根究底 使用Fiddler对目标App进行抓包
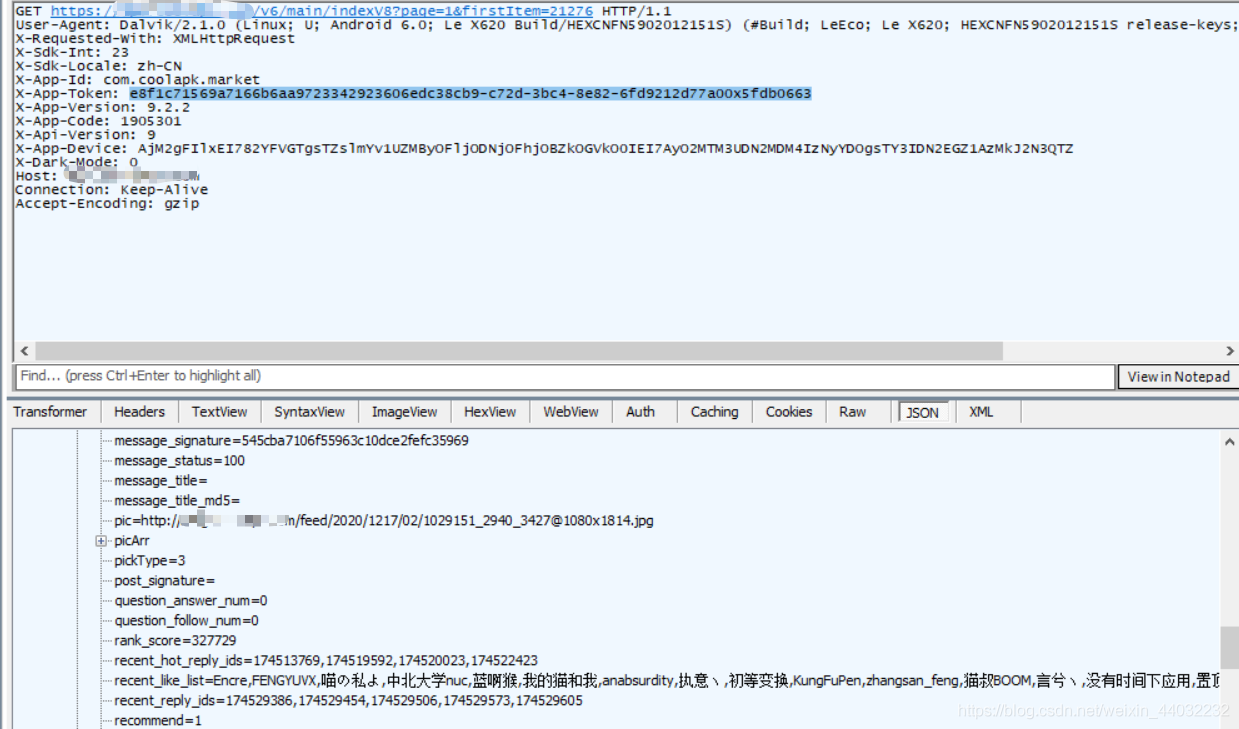
在 xpi.xoolapk.com Https协议中的包文可以看到请求参数中X-App-Token: e8f1c71569a7166b6aa9723342923606edc38cb9-c72d-3bc4-8e82-6fd9212d77a00x5fdb0663每次请求都是变化的,这里需要反编译app进行进一步的分析。
二、浮沙之上 解包逆向App定位关键方法
直接使用jadx解包反编译app并通过TextSearch找出相关参数定位相关代码。
通过jadx进入反编译后的apk中,搜寻X-App-Token,发现请求调用的函数字段,as。进入到as对应的方法中,找到赋值到as的方法,getAs()。
如上图所示定位到getAs方法,并且得知调用getAS需要传递两个参数context和str,其中context为当前app view的上下文环境,str初步推测为设备ID。
设备ID目前我们是不知道的,可以先对getAS进行基本的模拟入参(implementation)操作,来得到id的值。
import frida #导入frida模块
import sys #导入sys模块
jscode = """
Java.perform(function(){
var AuthUtils = Java.use('com.coolapk.market.util.AuthUtils') // 类的加载
AuthUtils.getAS.implementation = function(a,b){ // str为getAS的参数,原getAS需要几个参数就写几个
send(a);
send(b); // 这里的b就是str的值
var as = this.getAS(a,b); // 源函数有返回值 这里我们也将得到的返回值return
return as
};
});
"""
def on_message(message,data): #js中执行send函数后要回调的函数
if message["type"] == "send":
print("[*] {0}".format(message["payload"]))
else:
print(message)
process = frida.get_usb_device().attach('com.coolapk.market') # app包名
script = process.create_script(jscode) #创建js脚本
script.on('message',on_message) #加载回调函数,也就是js中执行send函数规定要执行的python函数
script.load() #加载脚本
sys.stdin.read()ef on_message(message,data): #js中执行send函数后要回调的函数
if message["type"] == "send":
print("[*] {0}".format(message["payload"]))
else:
print(message)
process = frida.get_usb_device().attach('com.coolapk.market') # app包名
script = process.create_script(jscode) #创建js上下文
script.on('message',on_message) #后处理函数
script.load()这种方法需要提前登录app并且浏览到个人页面以出发hook操作获取到想要的数据。 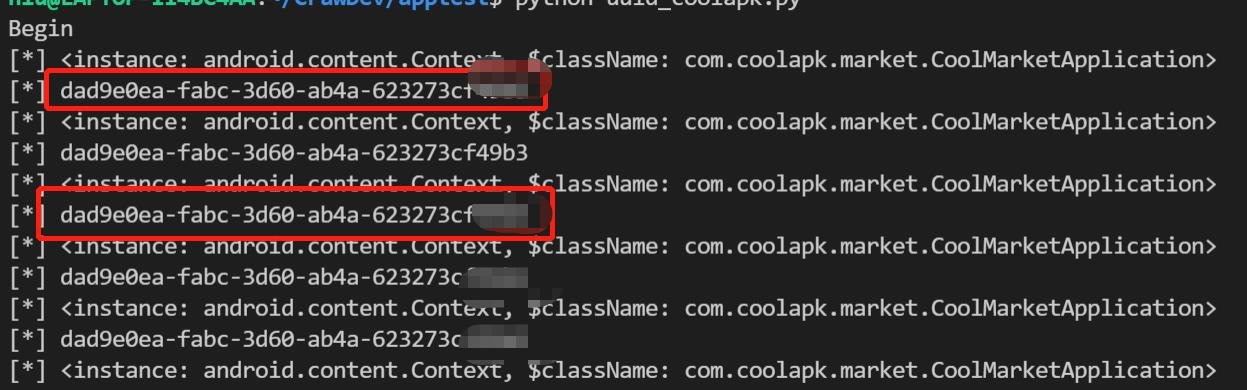
获取到Id为固定值dad9e0ea-fabc-3d60-ab4a-623273cfxx
三、磨刀霍霍 frida-rpc调用相关方法
拿到设备Id后,用拿到的id作为参数,再次主动调用getAs方法生成加密的token。
import codecs
import frida
import os
hook_code = '''
rpc.exports = {
// 函数名getheelo
getheelo: function(str){
send('heelo');
Java.perform(function(){
//拿到context上下文
var currentApplication = Java.use('android.app.ActivityThread').currentApplication();
var context = currentApplication.getApplicationContext();
// use 加载的类路径
var AuthUtils = Java.use('com.coolapk.market.util.AuthUtils');
//f = tt.$new();
var token= AuthUtils.getAS(context, str); // context,str组要自己组装
return token;
}
)
}
};
'''
def on_message(message, data):
if message['type'] == 'send':
print(message['payload'])
elif message['type'] == 'error':
print(message['stack'])
process = frida.get_usb_device().attach('com.coolapk.market')
script = process.create_script(hook_code)
script.on('message', on_message)
script.load()
script.exports.getheelo('dad9e0ea-fabc-3d60-ab4a-623273cfxx')
#前后Token对比 rpc调用生成的
4bdc740d8fff25d577ed9b28cca6b34cedc38cb9-c72d-3bc4-8e82-6fd9212d77a00x5fdb2185
#抓取得到的,每次都在变化,符合参数规律
e8f1c71569a7166b6aa9723342923606edc38cb9-c72d-3bc4-8e82-6fd9212d77a00x5fdb0663至此,通过rpc主动调用的这种方式可以获取到我们想要的随时变化token,而在频繁需求的实际采集取中我们可以将这些方法搭建一个web服务,来供上层方法使用。
4. 实践 APP数据采集
有了token后就可以对app进行抓取了
首先,通过抓包,确定app的首页头条资讯几个主要的请求url,分别有
首页头条
https://api.coolapk.com/v6/main/indexV8?page=1
头条文章详情
https://api.coolapk.com/v6/feed/detail?id=28222063&fromApi=%2Fv6%2Fmain%2FindexV8%3Fpage%3D1
文章详情评论
今日热榜页
[https://api.coolapk.com/v6/page/dataList?url=V9_HOME_TAB_RANKING&title=热榜&page=1&firstItem=8359]
找出每一项的文章ID字段为**entityId eg.entityId =**28493160,链接文章详情url
https://api.coolapk.com/v6/feed/detail?id=28493160&fromApi=V9_HOME_TAB_RANKING
以头条页为例,利用hooks获取到的token,构建app请求头
'X-App-Token': token
获取头条主要信息,文章id
def get_Headlines_page(page):
"""得到每个专栏每页文章id"""
headers = set_headers()
# 头条专栏
url = "https://api.coolapk.com/v6/main/indexV8?page="+str(page)
# 热榜专栏
#url = "https://api.coolapk.com/v6/page/dataList?url=V9_HOME_TAB_RANKING&title=%E7%83%AD%E6%A6%9C&page="+str(page)
response = requests.get(url, headers=headers)
if response.status_code == 200:
html = response.text
# print(html)
items = json.loads(html).get('data')
# print(data)
for item in items:
yield {
'id': item.get('entityId')
}通过拿到的文章id list (items) 获取头条文章详情(可能是想法和文章之间的一种,返回多字典列表
for item in items:
# print(item)
url = base_url.format(item.get('id'))
response = requests.get(url, headers=headers)
if response.status_code == 200:
item = json.loads(response.text).get('data')
if item == None:
continue #print(item)
yield {
'id': item.get('id'), # 文章id
'uid': item.get('uid'), # 用户id
'username': item.get('username'), # 用户名字
'title': item.get('title'), # 文章标题
'message': item.get('message'), # 文章内容
'likenum': item.get('likenum'), # 点赞数
'commentnum': item.get('commentnum'), # 评论数
'picArr': item.get('picArr') ,# 文章图片
'relative_phone': item.get('targetRow'), #话题
'phone':item.get('ttitle') #用户机型
}定义Pandas组结构容器,遍历每一个字典(data.items),加入pandas容器中
panda_dict = {
'id_arr' : [],
'uid_arr' : [] ,
'username_arr' : [] ,
'title_arr' : [] ,
'message_arr' : [] ,
'likenum_arr' : [] ,
'commentnum_arr' : [] ,
'picArr_arr' : [] ,
'relative_phone_arr' : [] ,
'phone_arr' : []
}
for (key,value) in data.items():
if not value:
panda_dict[key+'_arr'].append('无')
else:
if key=='relative_phone': # 话题字段情况(嵌入一级)
panda_dict[key+'_arr'].append(value['title'])
else:
panda_dict[key+'_arr'].append(value)定义Pandas dataframe 表头数据格式,最后输出到csv excel表格。注意,输出编码格式encoding='utf_8_sig',在一般情况下能解决大多数输出中文编码错乱的Bug。
dataframe = pd.DataFrame({'标题': panda_dict['title_arr'] , '文章id': panda_dict['id_arr'],
'用户id': panda_dict['uid_arr'] ,
'用户名字': panda_dict['username_arr'] , '点赞数': panda_dict['likenum_arr'] ,
'评论数': panda_dict['commentnum_arr'] , '话题': panda_dict['relative_phone_arr'] ,
'机型': panda_dict['phone_arr'] ,
'内容': panda_dict['message_arr'] , '文章图片': panda_dict['picArr_arr']
})
dataframe.to_csv("coolapk.csv", index=False, sep=',', mode='a', header=False, encoding='utf_8_sig')CSV线上预览地址
https://docs.qq.com/sheet/DY0tMTWNBUmluTFR4?tab=BB08J2
